Breaking Language Barriers: The Rise of Multilingual Large Language Models
A recent study by Microsoft has shed light on a significant digital divide: 88% of the world’s languages, spoken by 1.2 billion people, lack access to Large Language Models (LLMs). This issue stems from the dominance of English-centric LLMs, which are primarily trained on English data and cater to English speakers. Consequently, a vast majority of the global population is excluded from the benefits of LLMs. However, there’s hope on the horizon in the form of Multilingual LLMs, aiming to bridge this linguistic gap.
Multilingual LLMs: Breaking Down Language Barriers
Multilingual LLMs represent a breakthrough in language technology, capable of understanding and generating text in multiple languages. These models are trained on diverse datasets containing various languages, enabling them to perform tasks across different linguistic domains. Their applications range from translating literature into local dialects to facilitating real-time multilingual communication and content creation, offering a solution to the digital language gap.
Behind the Scenes: How Multilingual LLMs Work
Constructing a multilingual LLM involves meticulous preparation of multilingual text corpora and the adoption of suitable training techniques, often leveraging Transformer models. Techniques such as shared embeddings and cross-lingual transfer learning equip these models with the ability to understand linguistic nuances across different languages. This two-step process ensures a robust foundation in multilingual language understanding, paving the way for diverse downstream applications.
Exploring Multilingual LLMs: Notable Examples
Several noteworthy multilingual LLMs have emerged, each catering to specific linguistic needs and cultural contexts:
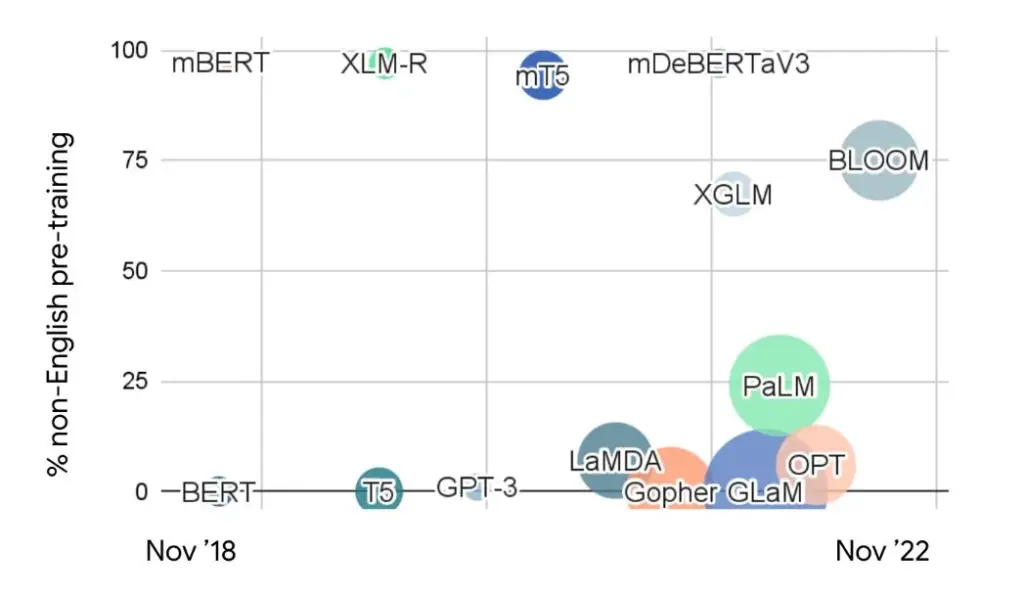
image source: ruder.io
- BLOOM: An open-access LLM boasting 176 billion parameters, capable of handling tasks in 46 natural and 13 programming languages.
- YAYI 2: Designed specifically for Asian languages, pre-trained on a multilingual corpus of over 16 Asian languages.
- PolyLM: Focuses on addressing challenges of low-resource languages by offering adaptation capabilities.
- XGLM: A multilingual LLM trained on a diverse set of over 20 languages, emphasizing inclusivity and linguistic diversity.
- mT5: Developed by Google AI, capable of handling 101 languages for tasks like translation and summarization.
Towards a Universal LLM: Challenges and Opportunities
While the concept of a universal LLM remains aspirational, current multilingual LLMs have showcased significant progress. However, they face challenges such as data quantity and quality concerns, resource limitations, model architecture adaptation, and evaluation complexities. Overcoming these hurdles requires collective efforts, including community engagement, open-source contributions, and targeted funding for multilingual research and development.
Empowering Linguistic Diversity
Multilingual LLMs hold immense potential in breaking language barriers, empowering under-resourced languages, and facilitating effective communication across diverse communities. As we navigate towards a more inclusive digital landscape, continued advancements in multilingual language technology are imperative for fostering global connectivity and understanding.
Grow your business with AI. Be an AI expert at your company in 5 mins per week! Free Newsletter – https://signup.bunnypixel.com